
앞서 배운 SELECT는 이미 만들어 놓은 테이블에서 데이터를 추출하는 구문이다. 이번에는 입력, 수정, 삭제하는 방법을 알아보자.
데이터베이스와 테이블을 만든 후에는 데이터를 변경하는, 즉 입력/수정/삭제하는 기능이 필요하다. 예를 들어 새로 가입한 회원을 테이블에 입력할 때는 INSERT 문을, 회원의 주소나 연락처가 변경되어 정보를 수정할 때는 UPDATE 문을 사용한다. 또 회원이 탈퇴해서 회원을 삭제할 때는 DELETE 문을 사용한다.
데이터 입력: INSERT
테이블에 행 데이터를 입력하는 기본적인 SQL 문은 INSERT이다.
INSERT 문의 기본 문법
INSERT는 테이블에 데이터를 삽입하는 명령이다. 기본적인 형식은 다음과 같다.
INSERT INTO 테이블 [(열1, 열2, ...)] VALUES (값1, 값2, ...)
INSERT 문은 별로 어려울 것이 없으니, 주의할 점만 몇 가지 확인해보자.
우선 테이블 이름 다음에 나오는 열은 생략이 가능하다. 열 이름을 생략할 경우에 VALUES 다음에 나오는 값들의 순서 및 개수는 테이블을 정의할 때의 열 순서 및 개수와 동일해야 한다. 간단한 테이블을 만들어서 연습해보자.
USE market_db;
CREATE TABLE hongong1 (toy_id INT, toy_name CHAR(4), AGE INT);
INSERT INTO hongon1 VALUES (1, '우디', 25);
이 예제에서 아이디 (toy_id)와 이름(toy_name)만 입력하고 나이(age)는 입력하고 싶지 않다면 다음과 같이 테이블 이름 뒤에 입력할 열의 이름을 써줘야 한다. 이 경우 생략한 나이(age) 열에는 아무것도 없다는 의미의 NULL 값이 들어간다.
INSERT INTO hongong1 (toy_id, toy_name) VALUES (2, '버즈');
열의 순서를 바꿔서 입력하고 싶을 때는 열 이름과 값을 원하는 순서에 맞춰 써주면 된다.
INSERT INTO hongong1 (toy_name, age, toy_id) VALUES ('제시', 20, 3);
자동으로 증가하는 AUTO_INCREMENT
AUTO_INCREMENT는 열을 정의할 때 1부터 증가하는 값을 입력해준다. INSERT에서는 해당 열이 없다고 생각하고 입력하면 된다. 단 주의할 점은 AUTO_INCREMENT로 지정하는 열은 꼭 PRIMARY KEY로 지정해줘야 한다.
우선 간단한 테이블을 만들어보자. 아이디 (toy_id) 열을 자동 증가로 설정했다.
CREATE TABLE hongong2 (
toy_id INT AUTO_INCREMENT PRIMARY KEY,
toy_name CHAR(4),
age INT);
이제 테이블에 데이터를 입력해보자. 자동 증가하는 부분은 NULL 값으로 채워 놓으면 된다. 결과를 보면 아이디(toy_id)에 1부터 차례대로 채워진 것을 확인할 수 있다.
INSERT INTO hongong2 VALUES (NULL, '보핍', 25);
INSERT INTO hongong2 VALUES (NULL, '슬링키', 22);
INSERT INTO hongong2 VALUES (NULL, '렉스', 21);
SELECT * FROM hongong2;

정리하면, AUTO_INCREMENT로 지정한 열은 1부터 자동으로 입력된다. 데이터를 입력할 때는 NULL로 지정하면 된다.
계속 입력하다 보면 현재 어느 숫자까지 증가되었는지 확인이 필요하다. 다음 SQL을 입력해보자. 3이 나올텐데, 자동 증가로 3까지 입력되었다는 의미이다.
SELECT LAST_INSERT_ID();
만약 AUTO_INCREMENT로 입력되는 다음 값을 100부터 시작하도록 변경하고 싶다면 다음과 같이 실행한다. ALTER TABLE 뒤에는 테이블 이름을 입력하고, 자동 증가를 100부터 시작하기 위해 AUTO_INCREMENT를 100으로 지정했다.
ALTER TABLE hongong2 AUTO_INCREMEMT=100;
INSERT INTO hongong2 VALUES (NULL, '재남', 35);
SELECT * FROM hongon2;

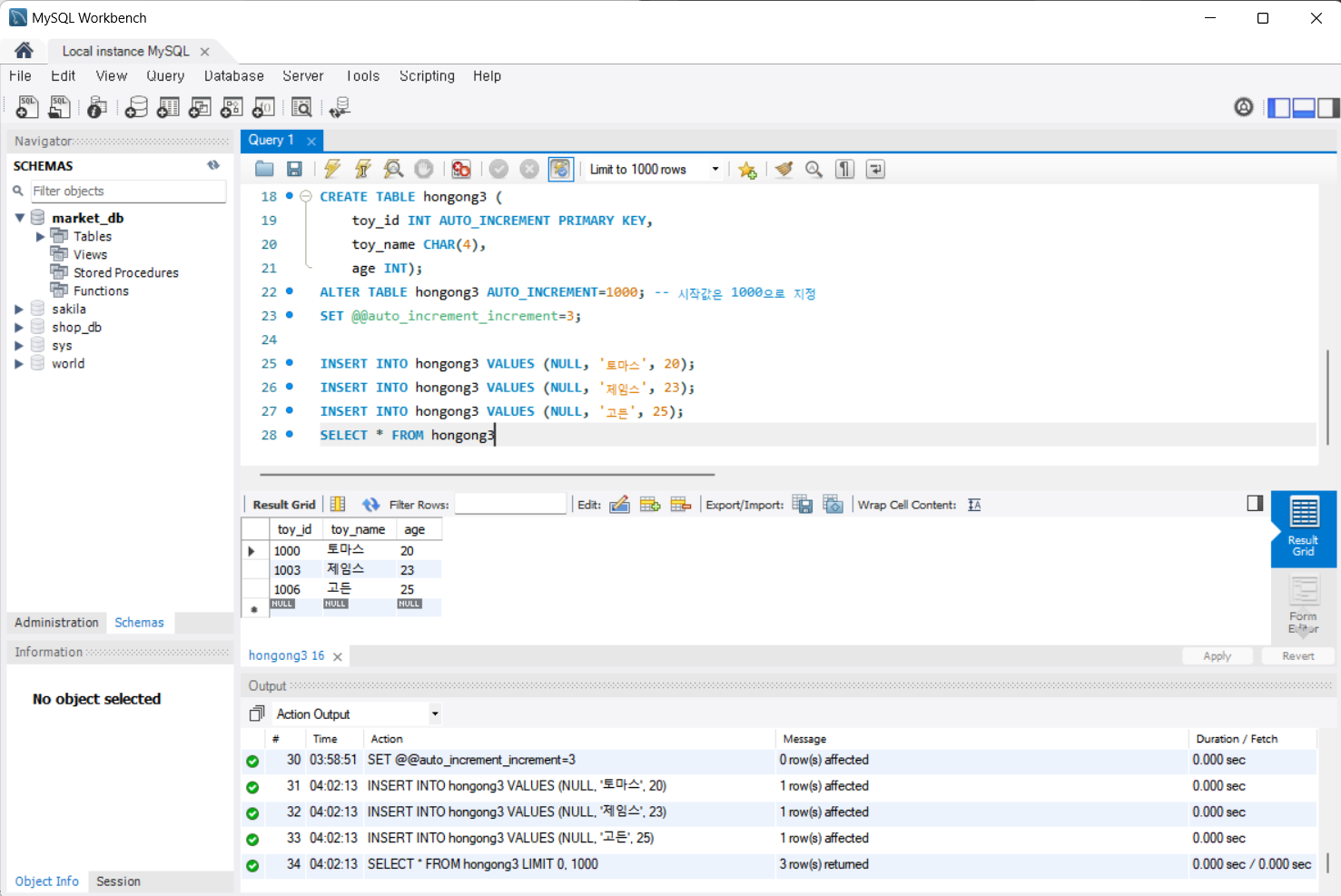
이번에는 처음부터 입력되는 값을 1000으로 지정하고, 다음 값은 1003, 1006, 1009, ...으로 3씩 증가하도록 설정하는 방법을 살펴보자.
이런 경우 시스템 변수인 @@auto_increment_increment를 변경시켜야 한다. 테이블을 새로 만들고 자동 증가의 시작값은 1000으로 설정한다. 그리고 증가값은 3으로 하기 위해 @@auto_increment_increment를 3으로 지정했다.
CREATE TABLE hongong3 (
toy_id INT AUTO_INCREMENT PRIMARY KEY,
toy_name CHAR(4),
age INT);
ALTER TABLE hongong3 AUTO_INCREMENT=1000; -- 시작값은 1000으로 지정
SET @@auto_increment_increment=3;
INSERT INTO hongong3 VALUES (NULL, '토마스', 20);
INSERT INTO hongong3 VALUES (NULL, '제임스', 23);
INSERT INTO hongong3 VALUES (NULL, '고든', 25);
SELECT * FROM hongong3
다른 테이블의 데이터를 한 번에 입력하는 INSERT INTO ~ SELECT
많은 양의 데이터를 지금까지 했던 방식으로 직접 타이핑해서 입력하려면 오랜 시간이 걸린다. 다른 테이블에 이미 데이터가 입력되어 있다면 INSERT INTO ~ SELECT 구문을 사용해 해당 테이블의 데이터를 가져와서 한 번에 입력할 수 있다.
INSERT INTO 테이블_이름 (열_이름1, 열_이름2, ...)
SELECT 문;
주의할 점은 SELECT 문의 열 개수는 INSERT할 테이블의 열 개수와 같아야 한다. 즉 SELECT의 열이 3개라면 INSERT될 테이블의 열도 3개여야 한다.
먼저 MySQL을 설치할 때 함께 생성된 world 데이터베이스의 city 테이블의 개수를 조회해보자. 앞에서 배운 COUNT(*)를 사용하자. 4079개가 나온다. 도시가 4079개 저장되어 있다는 의미이다.
SELECT COUNT(*) FROM world.city;
이번에는 world.city 테이블의 구조를 살펴보자. DESC 명령으로 테이블 구조를 확인할 수 있다. DESC는 Describe의 약자로 테이블의 구조를 출력해주는 기능을 한다. 즉, CREATE TABLE을 어떻게 했는지 예상할 수 있다.
DESC world.city;

LIMIT을 사용해서 5건 정도만 살펴보자.
SELECT * FROM world.city LIMIT 5;

이 중에서 도시 이름(Name)과 인구(Population)를 가져와보자. 먼저 테이블을 만들자. 테이블은 DESC로 확인한 열 이름(Field)과 데이터 형식(Type)을 사용하면 된다. 필요하다면 열 이름은 바꿔도 상관없다.
CREATE TABLE city_popul (city_name CHAR(35), population INT);
이제는 world.city 테이블의 내용을 city_popul 테이블에 입력해보자. 결과 메시지로는 4079행이 처리된 것으로 나온다. 이렇게 다른 테이블의 데이터를 한 번에 가져오는 방법을 확인해 보았다.
INSERT INTO city_popul
SELECT Name, Population FROM world.city;

데이터 수정: UPDATE
회원의 주소가 변경되는 경우처럼 행 데이터를 수정해야 하는 경우도 빈번하게 발생한다. 이럴 때 UPDATE를 사용해서 내용을 수정한다.
UPDATE 문의 기본 문법
UPDATE는 기본에 입력되어 있는 값을 수정하는 명령이다. 기본적인 형식은 다음과 같다.
UPDATE 테이블_이름
SET 열1=값1, 열2=값2, ...
WHERE 조건;
앞에서 생성한 city_popul 테이블의 도시 이름 (city_name) 중에서 'seoul'을 '서울'로 변경해보자. 새 쿼리 창을 열고 다음 SQL을 실행하자.
USE market_db;
UPDATE city_popul
SET city_name = '서울'
WHERE city_name = 'seoul';
SELECT * FROM city_popul WHERE city_name = '서울';
결과를 보면 한글로 잘 변경되었다.

필요하면 한꺼번에 여러 열의 값을 변경할 수도 있다. 콤마(,)로 분리해서 여러 개의 열을 변경하면 된다. 다음 SQL은 도시 이름(city_name)인 'New York'을 '뉴욕'으로 바꾸면서 동시에 인구(population)는 0으로 설정하는 내용이다.
UPDATE city_popul
SET city_name = '뉴욕', population = 0
WHERE city_name = 'New York';
SELECT * FROM city_popul WHERE city_nae = '뉴욕';

WHERE가 없는 UPDATE 문
UPDATE는 사용법이 간단하지만 주의할 사항이 있다. UPDATE 문에서 WHERE 절은 문법상 생략이 가능하지만, WHERE 절을 생략하면 테이블의 모든 행의 값이 변경된다. 일반적으로 전체 행의 값을 변경하는 경우는 별로 없으므로 주의해야 한다.
그렇다면 전체 테이블의 내용은 어떤 경우에 변경할까? city_popul 테이블의 인구(population) 열은 1명 단위로 데이터가 저장되어 있다. 아프가니스탄의 도시 카불(Kabul)의 경우 인구(population)가 1,780,000인데, 이 단위를 10,000명 단위로 변경하면 좀 더 읽기 쉬울 것이다.
다음 SQL을 이용해서 모든 인구 열(population)을 한꺼번에 10,000으로 나눌 수 있다. 5개행만 조회해보자. 인구 열이 10,000명 단위로 변경되어서 한눈에 보기 편해졌다.
UPDATE city_popul
SET population = population / 10000;
SELECT * FROM city_population LIMIT 5;
데이터 삭제: DELETE
테이블의 행 데이터를 삭제해야 하는 경우도 발생한다. 예를 들어 회원이 탈퇴한 경우에 해당 회원의 정보를 삭제해야 한다. 이럴때 DELETE는 행 데이터를 삭제한다.
DELETE도 UPDATE와 거의 비슷하게 사용할 수 있다. DELETE는 행 단위로 삭제하며, 형식은 다음과 같다.
DELETE FROM 테이블이름 WHERE 조건;
city_popul 테이블에서 'New'로 시작하는 도시를 삭제하기 위해 다음과 같이 실행하자. 도시 이름 앞에 New가 들어가는 도시는 Newcastle, Newport, New Orleans 등 11개 정도가 있다.
DELETE FROM city_popul
WHERE city_name LIKE 'New%';

UPDATE와 마찬가지로 DELETE 문도 WHERE 절이 생략되면 전체 데이터를 삭제하므로 주의하자.
만약 'New' 글자로 시작하는 11건의 도시를 모두 지우는 것이 아니라 'New' 글자로 시작하는 도시 중 상위 몇 건만 삭제하려면 LIMIT 구문과 함께 사용하면 된다. 다음과 같이 실행하면 'New' 글자로 시작하는 도시 중에서 상위 5건만 삭제된다.
DELETE FROM city_popul
WHERE city_name LIKE 'New%'
LIMIT 5;
대용량 테이블의 삭제
만약 몇억 건의 데이터가 있는 대용량의 테이블이 더 이상 필요 없다면 어떻게 삭제하는 것이 좋을까?
우선 대용량 테이블을 3개 준비하자. 다음 SQL을 실행하면 각각 몇십만 건의 데이터를 가진 big_table1, big_table2, big_table3이 생성된다. 데이터는 모두 동일하다. 결과를 확인하면 44만건 정도의 데이터가 들어있다.
CREATE TABLE big_table1 (SELECT * FROM world.city, sakila.country);
CREATE TABLE big_table2 (SELECT * FROM world.city, sakila.country);
CREATE TABLE big_table3 (SELECT * FROM world.city, sakila.country);
SELECT COUNT(*) FROM big_table1;
이제 동일한 내용의 대용량 테이블 3개를 DELETE, DROP, TRUNCATE 각각 다른 방법으로 삭제해보자.
우선 DELETE 문은 삭제가 오래 걸린다. 지금은 3.5초 정도가 걸리는데 만약 데이터가 수억 건 이상이라면 훨씬 오랫동안 삭제할 수도 있다. DROP 문은 테이블 자체를 삭제한다. 그래서 순식간에 삭제된다. TRUNCATE 문도 DELETE와 동일한 효과를 내지만 속도가 무척 빠르다. DROP은 테이블이 아예 없어지지만, DELETE와 TRUNCATE는 빈 테이블을 남긴다.
DELETE FROM big_table1;
DROP TABLE big_talbe2;
TRUNCATE TABLE big_table3;
결론적으로 대용량 테이블의 전체 내용을 삭제할 때 테이블 자체가 필요 없을 경우에는 DROP으로 삭제하고, 테이블의 구조는 남겨놓고 싶다면 TRUNCATE로 삭제하는 것이 효율적이다.
'혼공학습단 12기' 카테고리의 다른 글
| [혼공S] 04 - 1 'MySQL의 데이터 형식' 정리 (0) | 2024.07.13 |
|---|---|
| [혼공S] 2주차 마무리 (0) | 2024.07.12 |
| [혼공S] 03 - 2 '좀 더 깊게 알아보는 SELECT 문' 정리 (1) | 2024.07.09 |
| [혼공S] 03 - 1 '기본 중에 기본 SELECT ~ FROM ~WHERE' 정리 (0) | 2024.07.08 |
| [혼공S] 1주차 미션 (0) | 2024.07.07 |