BFS/DFS는 그래프를 탐색하기 위한 대표적인 두 알고리즘이다.
나는 정말 아무것도 모르는 감자이기 때문에,
BFS/DFS를 다루기 이전에 우선 탐색과 그래프의 개념을 정확하게 이해할 필요가 있었다.
탐색이란?
탐색이란 많은 양의 데이터 중에서 원하는 데이터를 찾는 과정을 의미한다.
주로 그래프, 트리 등의 자료구조 안에서 탐색을 진행하게 된다.
그래프(GRAPH)란?
그래프는 여러개의 노드(node)와 이들을 연결하는 간선(edge)으로 이루어진 자료구조이다.
이때 노드를 정점(vertex)이라고도 말한다.
그래프를 탐색한다는 것은 하나의 노드를 시작으로 다수의 노드를 방문하는 것을 말한다.

프로그래밍에서 그래프는 크게 2가지 방식으로 표현할 수 있는데 '인접 행렬' 방식과 '인접 리스트' 방식이다.
인접 행렬: 2차원 배열로 그래프의 연결 관계를 표현하는 방식
인접 리스트: 리스트로 그래프의 연결 관계를 표현하는 방식
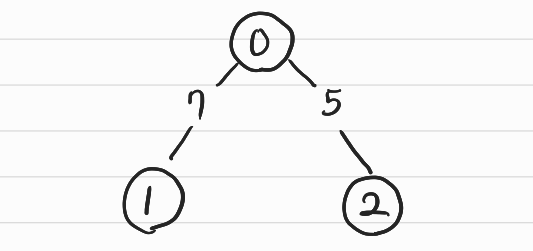
인접 행렬 방식은 2차원 배열에 각 노드가 연결된 형태를 기록하는 방식이다.
연결 되어 있지 않은 노드끼리는 무한(infinity)의 비용이라고 작성한다.
실제로 그래프를 인접 행렬 방식으로 처리할 때는 다음과 같이 데이터를 초기화한다.
graph = [
[0 , 7, 5],
[7 , 0, INF ],
[5 , INF , 0]
]

인접 리스트 방식은 모든 노드에 연결된 노드에 대한 정보를 차례대로 연결하여 저장한다.
C++이나 자바에서는 별도로 연결 리스트 기능을 위한 라이브러리를 이용해야 하고,
파이썬은 리스트 자료형이 배열과 리스트의 기능을 모두 기본으로 제공한다.
따라서 파이썬에서는 인접 리스트를 이용해 그래프를 표현하고자 할 때, 단순히 2차원 리스트를 이용하면 된다.
실제로 그래프를 인접 리스트 방식으로 처리할 때는 다음과 같이 데이터를 초기화한다.
# 행(Row)이 3개인 2차원 리스트로 인접 리스트 표현
graph = [[] for _ in range (3)]
# node 0에 연결된 노드 정보 저장 (노드, 거리)
graph[0].append((1,7))
graph[0].append((2,5))
# node 1에 연결된 노드 정보 저장
graph[1].append((0, 7))
# node 2에 연결된 노드 정보 저장
graph[2].append((0, 5))

이 두 방식에는 어떤 차이가 있을까?
메모리 측면에서 보자면 인접 행렬 방식은 모든 관계를 저장하므로 노드 개수가 많을수록 메모리가 불필요하게 낭비된다.
반면에 인접 리스트 방식은 연결된 정보만을 저장하기 때문에 메모리를 효율적으로 사용한다.
하지만 이 때문에 두 노드가 연결되어 있는지에 대한 정보를 얻는 속도가 느리다.(찾아 다녀야 하니까)
인접 리스트 방식은 연결된 데이터를 하나씩 확인해야 하기 때문이다.
다음 포스팅에서는 인접 행렬 방식, 인접 리스트 방식을 응용한 DFS에 대해 알아보도록 하자!
오늘 하루도 쌓였다.
'코딩 테스트 연습 > 이론' 카테고리의 다른 글
| BFS/DFS(2) (2) | 2024.02.28 |
|---|---|
| BFS/DFS(1) (0) | 2024.01.02 |
| 그래프 vs 트리 (2) | 2024.01.01 |
| Greedy (1) | 2023.12.17 |